![[MAP Logo]](../../maplogo1.gif)
C.A. Walsh,
Phase Transformations Group,
Department of Materials Science and Metallurgy,
Pembroke Street,
University of Cambridge,
Cambridge CB2 3QZ, U.K.
E-mail: caw4@cus.cam.ac.uk
Added to MAP: July 2002.
The BIGBACK program by David Mackay can be used to train a neural network from a series of experimental datasets. These routines read the output files from the BIGBACK program and use them to make predictions for any given set of inputs. The size of the error bars on the predicted values are also evaluated.
| Language: | FORTRAN |
| Product form: | Source code |
MODEL1(ND,INM,IHU,SNU,PMAX,PMIN,WGTFILE) DOUBLE PRECISION PMAX(20), PMIN(20), SNU(50) CHARACTER*9 WGTFILE(50) INTEGER ND, INM, IHU(50) NORM(ND,X0,XN,PMAX,PMIN) DOUBLE PRECISION X0(20), XN(20), PMAX(20), PMIN(20) INTEGER ND GETV(ND,IHU,SNU,PMAX,PMIN,XN,WGTFILE,ERR0,ANS0,ANS0P,ANS0M) DOUBLE PRECISION PMAX(20), PMIN(20), XN(20) DOUBLE PRECISION SNU, ERR0, ANS0, ANS0P, ANS0M CHARACTER*9 WGTFILE INTEGER ND, IHU
A neural network is a non-linear mathematical equation for expressing one physical quantity, y, as a function of a set of input parameters, xj:

The weights, wi and wij, and biases are determined using the BIGBACK program written by David Mackay1,2 from a series of known input parameters and measured output values (known as training the network), and are stored in a weights file. The BIGBACK program is also capable of calculating error bars, based on the probability distribution of the dataset used to train the network. In order to facilitate these calculations, the lu decomposition of the Hessian matrix is stored in a weights.lu output file. Further details about lu decomposition can be found by reference to Numerical Recipes4.
In general the best results are obtained by averaging the outputs from several different neural networks (committee result)3. The error from a committee of N networks is given in reference 3 as
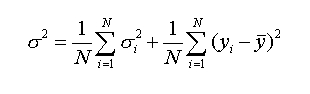
This module contains a group of routines which can be used to obtain predictions from a neural network or committee of networks and calculate the size of the error bar. The weights and weights.lu output files are required as input files. These files should be stored in a sub-directory called w. The names of the weights files for each network in the committee should have exactly 7 characters (excluding the sub-directory name), and the corresponding lu decomposition files should have the suffix .lu.
e.g.
wgts101 and wgts101.lu wgts102 and wgts102.lu wgts103 and wgts103.lu
The souce code contains a complete program (except for routine LUBKSB) which gives an example of how the routines are used, including how to evaluate the overall error from a committee of neural networks.
NB The BIGBACK program is capable of considering a number of different forms to the non-linear equation relating the output to the input parameters. This program is strictly limited to the form given above. i.e., a linear output-layer activation function and a tanh activation function for the hidden layer.
NB For copyright reasons, the subroutine LUBKSB (absolutely essential for the operation of this module) is not included with this set of routines. It is a Numerical Recipes4 subroutine and must be acquired from a suitable source. (It is not a long routine and can be typed in very quickly and easily, if necessary.)
NB Users may find it necessary to add a carriage return to the end of each weights file in order to enable the program to read them.
The routines contained in the module are:
MODEL1
This sets up the required arrays and parameters with details of the neural networks: number of input variables and their normalisation factors; number of models in the committee; number of hidden nodes in each network; sigma_nu values; filenames of the weight files. All these need to be inserted into the subroutine by the user.
NORM
This subroutine is called to normalise the input parameters.
GETV
This subroutine is the core part of the program. It is called once for each network in the committee. Each time it returns the calculated output value and its error. This routine makes calls to the following subroutines:
None.
No information supplied.
None.
IMPLICIT DOUBLE PRECISION (A-H,O-Z), INTEGER(I-N)
DOUBLE PRECISION SNU(50),PMAX(20),PMIN(20),XN(20),X0(20)
INTEGER IHU(50)
CHARACTER*9 WGTFILE(50),BLANK
C
BLANK = ' '
DO 100 L1=1,50
WGTFILE(L1) = BLANK
100 CONTINUE
C
C Call subroutine to set the maximum and minimum parameter values for the
C model and set the number of input parameters and hidden variables etc.
C
CALL MODEL1(ND,INM,IHU,SNU,PMAX,PMIN,WGTFILE)
C
C Read in the parameters (not normalised) and store in X0
C
READ(*,*) (X0(J),J=1,ND)
C
C Normalise the parameters. Put normalised parameters in XN
C
CALL NORM(ND,X0,XN,PMAX,PMIN)
ANSR = 0D0
ANSS = 0D0
ERR1 = 0D0
DO 120 L1=1,INM
CALL GETV(ND,IHU(L1),SNU(L1),PMAX,PMIN,XN,WGTFILE(L1),
+ ERR0,ANS0,ANS0P,ANS0M)
ANSR = ANSR + ANS0
ANSS = ANSS + ANS0*ANS0
ERR1 = ERR1 + ERR0*ERR0
120 CONTINUE
ERR1 = ( ERR1 + ANSS - ANSR*ANSR/INM )/INM
ERR1 = SQRT(ERR1)
ANS1 = ANSR / INM
ANS1M = ANS1 - ERR1
ANS1P = ANS1 + ERR1
C
C Write out the results
C
WRITE(*,1)
WRITE(*,2) ANS1,ERR1,ANS1M,ANS1P
STOP
1 FORMAT(///' VALUE ERROR RANGE')
2 FORMAT(2X,F6.2,2X,F6.3,2X,F6.2,' - ',F6.2)
END
0.8 1.5 1600.0 30.0 The sample weights files can be downloaded with the source code.
VALUE ERROR RANGE
1.62 0.243 1.38 - 1.86
Numerical Recipes Subroutine LUBKSB
neural, network, weights, error, calculation, evaluate
MAP originated from a joint project of the National Physical Laboratory and the University of Cambridge.
MAP Website administration / map@msm.cam.ac.uk