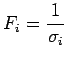
|
Richard Kemp
Once a neural network model has been created, it is frequently desirable to use the model backwards and identify sets of input variables which result in a desired output value. The large numbers of variables and non-linear nature of many materials models can make finding an optimal set of input variables difficult.
Here, we can use a genetic algorithm to try and solve the problem.
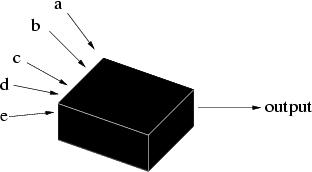
What are genetic algorithms? Genetic algorithms (GAs) are search algorithms based on the mechanics of natural selection and genetics as observed in the biological world. They use both direction (``survival of the fittest'') and randomisation to robustly explore a function. Importantly, to implement a genetic algorithm it is not even necessary to know the form of the function; just its output for a given set of inputs (Figure 1).
What do we mean by robustness? Robustness is the balance between efficiency and efficacy necessary for a technique to be of use in many different environments. To help explain this, we can compare other search and optimisation techniques, such as calculus-based, enumerative, and random searchs.
Calculus-based approaches assume a smooth, unconstrained function and either find the points where the derivative is zero (easier said than done) or follow a direction related to the local gradient to find the local high point (hill climbing). These techniques have been heavily studied, extended and rehashed, but it is simple to demonstrate their lack of robustness.
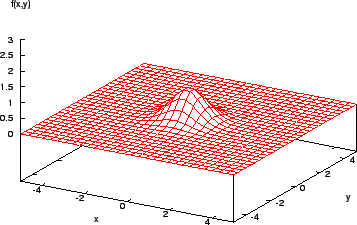
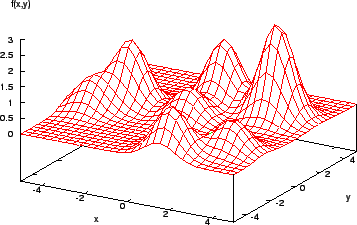
Consider the function shown in Figure 2. It is easy for a calculus-based method to find the maximum here (assuming the derivative of the function can be found...!). However, a more complex function (Figure 3) shows that the method is local - if the search algorithm starts in the region of a lower peak, it will miss the target, the highest peak.
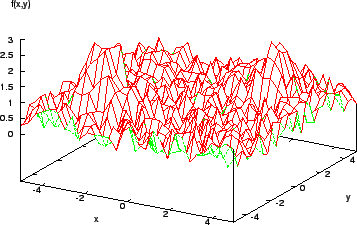
Once a local maximum is reached, further improvement requires a random restart or something similar. Also, the assumption that a function is smooth, differentiable, and explicitly known is seldom respected in reality. Many real-world models are fraught with discontinuities and set in noisy multimodal search spaces (Figure 4).
|
|
While calculus-based methods can be very efficient in certain environments, the inherent assumptions and local nature means they are insufficiently robust across a wide spectrum of problems.
In such cases, it may be tempting to try and calculate the whole surface and find maxima that way. This brute force method is, unsurprisingly, highly inefficient. Alternatively, a random-walk approach may be used to explore the surface. This is also inefficient - although both of these methods retain their applicability across a wide range of problem types, unlike the calculus-based approach.
How, then, do genetic algorithms (GAs) differ from these methods? Drawing from biological genetics and natural selection, there are three fundamental differences:
This combination of properties allows a large, multi-parameter space to be explored efficiently and efficaciously, provided they are applied judiciously.
To start with, it is necessary to encode the parameter set for a model into a chromosome, Xi. This is a way of expressing the information that allows for various forms of mutation to occur in the parameter set, and consists of a set of genes, [xi1, xi2, xi3, xi4, ...]. This set of genes, when given to the model as inputs, will give the output fi. The chromosomes are then ranked according to a fitness factor, Fi, describing how well they perform relative to expectation and each other.
The chromosomes are then allowed to breed (with a likelihood proportional to fitness) and mutate. In practice, evolution occurs in two ways - crossover (see tables 1 and 2) and random variation. In this example, mutation would be represented by flipping a randomly chosen bit. In a neural network optimisation GA, mutation would involve a small variation - plus or minus - in a randomly chosen gene.
|
|
This simple example demonstrates a simple optimisation problem. For complex multi-parameter models, larger populations will be necessary for efficient exploration of the parameter space and, to further increase efficiency, multiple populations may be used. This allows a range of forms of variation to occur with every generation. Typically, say, from a population of 20 chromosomes, for the next generation the best (fittest) may be preserved unchanged (elitism); a further 18 places, for crossover and mutation, may be randomly filled based on their relative fitnesses (as in Table 1); and the final place filled by a completely new, randomly generated chromosome.
To summarise, the process is:
The algorithm is repeated until:
For Bayesian artificial neural networks (ANNs), we have a set of input parameters and two output values - the prediction from the network and its associated uncertainty. Assuming that we want to avoid wild predictions, we can use a fitness function Fi which incorporates both of these outputs, for example
where
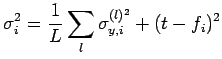 |
(2) |
in which L is the number of models in the predicting committee,
![]() is the uncertainty associated with the prediction of each committee member l, t is the target output for the optimisation, and fi is the committee prediction.
is the uncertainty associated with the prediction of each committee member l, t is the target output for the optimisation, and fi is the committee prediction.
The basic chromosome, as mentioned above, can consist of the set of inputs to the network.
There are some ways to help optimise the procedure when applied to ANNs. The first is that it is desirable to avoid finding an "optimal" input set with non-physical values. As all inputs are normalised before the neural network is applied, it is perfectly possible to make predictions for a steel containing -1 wt% carbon, for example. This can be avoided in two ways - by restricting the range of the genes during "mutation" and the generation of new chromosomes, or by adding terms to the fitness function to additionally penalise such unphysical genes and hence use evolution against them.
In addition, because single-point crossover efficiently selects for combinations of genes that are close together in the chromosome but tends to split up combinations that are far apart (Figure 5), inputs that are likely to have a combined effect should be grouped close to one another in the chromosome. This effect can be avoided by using uniform crossover - selecting genes at random from either parent (Figure 6) - although this will make the algorithm less efficient at finding very ``fit'' combinations.
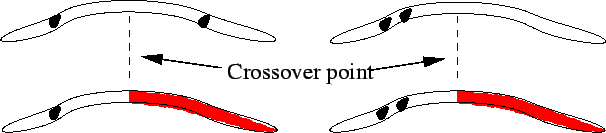
|
|
It is also common to have, as inputs to an ANN model, variables which are functions of other input variables, such as, say, Arrhenius forms like
![]() as well as the temperature itself. In this case care must be taken that one is always a function of the other, and that they are not allowed to vary independently. We may additionally have a number of input variables which we wish to keep constant - if we are trying to optimise a steel for performance at a particular temperature, say.
as well as the temperature itself. In this case care must be taken that one is always a function of the other, and that they are not allowed to vary independently. We may additionally have a number of input variables which we wish to keep constant - if we are trying to optimise a steel for performance at a particular temperature, say.
In a simple genetic algorithm run, there are a number of basic parameters, as shown in Table 3.
|
The computing parameters are simple - using additional populations allows multiple areas of the network to be explored at once but increases the computing power required - and how long do you need to run the procedure for? The GA-specific parameters require a little more explanation, although population size is self-explanatory.
The crossover rate is the proportion of each new generation which undergoes crossover. The mutation rate is the rate at which mutations occur. In optimising a neural network model, we need a relatively high mutation rate, where a mutation is a small nudge δσ of a gene value. The rate of population mixing is the frequency that different populations are allowed to undergo crossover.
The effects of these parameters are explored in Delorme (2003)2. To summarise, 3 populations of 20 chromosomes running for 3000 generations is a good start for many Bayesian neural network optimisations, with a crossover rate of 90% (i.e. for a population of 20, 18 chromosomes are chosen using the roulette wheel method and crossed with another 18 using the same method, producing 18 offspring). The remaining slots are filled with the best performer from the previous population, and a wholly new randomly-generated chromosome. Every generation, one gene in the population is mutated.
The preservation of the elite performer simulates some of the features of local-maximum search techniques, allowing the optimal chromosome found so far to be preserved in the population unchanged. This can occasionally lead to the algorithm getting "stuck" at a sub-optimal solution if the model is very multi-modal, but the use of multiple populations and a high mutation rate minimise this probability, as does the inclusion of a new set of genes in every generation.
The chief problems associated with GA optimisation are
A constrained problem is one in which there are limits to the values that can be used as inputs to the network (such as a chemical composition which cannot be negative), although the nature of ANNs and GAs are naturally unconstrained. Two ways to fix this problem are mentioned above - restriction of the mutation process or modification of the fitness function to reflect the constraints and penalise those chromosomes that transgress them.
GA deceptive functions are functions which confound the GA by selecting for an individual gene at the expense of another gene, when a combination of the two would lead to optimal fitness. This leads, in some cases, to the elimination from the genepool of optimal values of those genes. This can be avoided by elitism (as mentioned above), the use of multiple populations, and a high mutation rate to reintroduce any genes lost.
Premature convergence is a similar problem - if a chromosome is far fitter than its rivals early on, it can come to dominate a population, leading to loss of genes which may, later, lead to better solutions. This can be avoided by employing a high mutation rate, and also through fitness scaling. This is a process that re-scales the absolute Fi with respect to the average of the population, so that the fittest chromosome is only, say, twice as likely to be chosen for cross-breeding as the average chromosome.
This procedure also aids the problem of lack of convergence towards the end of an optimisation procedure. In this case, a population of similarly high-performing chromosomes will not compete strongly with one another. Fitness scaling here retains the competition between chromosomes and keeps the algorithm efficient. A potential danger is that any poor performers left in the population may end up with negative Fi after re-scaling. In this case, these chromosomes can be assigned a fitness of zero.
An overly high mutation rate makes the process inefficient, as the GA then starts to resemble a random walk rather than a directed process.
Lastly, some thought must be given to the meaning of "fitness". When designing a genetic algorithm, what do you actually want it to do? For finding a set of optimal values that will give a specific output from a neural network, the answer is easy. When applying GAs to other problems, defining an appropriate fitness function can make all the difference between success and an unexpectedly random result.
A neural network model was created to predict the effect of irradiation on the yield stress (YS) on a class of steels known as reduced-activation ferritic/martensitic (RAFM) steels3. In order to find alloys which exhibited moderate irradiation hardening, a genetic algorithm was used.
Inputs to the neural network included chemical composition, irradiation temperature and damage level, tensile test temperature, radiation-induced helium levels, and degree of cold working prior to irradiation. In this case, all we were interested in was an optimised ideal chemical composition. Therefore, all other parameters were fixed (including compositional impurity levels). In addition, the Cr content was fixed - Cr strongly affects radiation embrittlement with a minimum around 9 wt% Cr, and this was a rough attempt to optimise for both properties without having to extensively modify existing GA code.
The chromosome therefore consisted of the major alloying elements in RAFM steels: C, W, Mo, Ta, V, Si and Mn. 3 populations of 20 chromosomes were randomly generated from within appropriate limits for each gene. The program then went through following loop for each population:
Every 400 generations, the best performer in each population was allowed to crossbreed with the best performers from each other population. This was to prevent any populations getting stuck in a local (rather than a global) maximum. The calculation was run for 3000 generations in total, which took about 2-and-a-half weeks. The results for a 20 dpa4 irradiation at 700 K are shown in Table 4.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The fact that all three populations predict very similar results (there were some differences in the third decimal places) strongly suggests that this is a global maximum fitness. Note, though, that this is not necessarily the lowest possible yield stress in the ANN model, but the closest to the target YS, given the additional constraints (i.e. the fixed inputs not in the chromosome).
It is of course possible to create a fitness function which takes into account multiple properties from multiple network models and optimises for all of them, although this has not yet been done in our group.
There are some simple questions to test understanding of the basic concepts here.
Genetic Algorithms in Search, Optimization and Machine Learning by David Goldberg (pub. Addison Wesley, 1989) is an excellent overview of the field and the theory behind it.
A GA code for neural networks is also available through the MAP website:
https://www.phase-trans.msm.cam.ac.uk/map/mapmain.html
The creation of this document was supported by the Higher Education Funding Council for England, via the U.K. Centre for Materials Education.
June 5th 2006
| Superalloys | Titanium | Bainite | Martensite | Widmanstätten ferrite |
| Cast iron | Welding | Allotriomorphic ferrite | Movies | Slides |
| Neural Networks | Creep | Mechanicallly Alloyed | Theses |
| PT Group Home | Materials Algorithms |

|

|